HTK��ȫ���ǡ�Hidden Markov Model Toolkit������Ӣ�����Ŵ�ѧ����ѧԺ�������������ɷ�ģ�ͣ�������Ϊ����ģ�ͣ����߰������Է�����Ч�Ľ�������������ģ�͡�����ģ���������˹������������ųɹ���Ӧ�ã���������ʶ�𣬵�ǰ����������������ʶ��ϵͳ���ǻ�������ģ�ͽ����ġ�HTK�Ŀ���Ҳ��Ҫ���������ʶ���Ӧ�ü��о���
HTK��һ����Դ���߰���������http://htk.eng.cam.ac.uk/����������أ����߰��а�����������ģ�鼰���ߣ������ô�C����д�ɵģ���������H��ͷ������Ҳ�зdz���ϸ���ĵ��ɹ��ο���
��������ѵ������
����������Ҫ¼���Բɼ��㹻���������ݣ����ڡ����رա���ʼ��ֹͣ�����ĸ������Ҫ¼һЩ��Ӧ������������ͬʱҲ��Ҫ��¼�µ�������һЩ�ı�ע��¼���ͱ�ע���Բ���HTK���߰��е�HSLab����ɡ�
�����������������С�HSLab��.sig����Ȼ������Rec������ʼ¼���������Stop����¼����������ʱ�ͻ��ڵ�ǰĿ¼������һ����Ϊ����_0.sig���ļ����ٽ���һ��¼�������ɡ���_1.sig�����Դ����ơ�Ĭ�ϵ�¼��������Ϊ16kHz�����Dz���Ĭ�ϵ����þͿ����ˡ�
¼������Ҫ���������мı�ע����עҲ����HSLab���ߣ����к�Mark������ѡ����Ҫ��ע��������Labelas���������ע�ķ��ţ�Ȼ��س�ȷ�����ɡ��ڱ��ʵ������У�ÿ�������������ǹ���������ʣ�����ֻ��Ҫ��ע��3�����֣���ʼ�������֣����Ϊsil����������������֣����Ϊ����ʣ��硰�����������������֣����Ϊsil������ע��ɣ������Save�������棬������һ����Ϊ��lab�����ļ���
������ȡ
����ʶ��ϵͳ����ֱ���������ź��Ͻ���ʶ�𣬶�����Ҫ����������ȡ��������֡���Ӵ�����ȡƵ�����ף�����ȷ����ȡ�����������ӽ��ղ������ܶ�ı����������ݵ���Ϣ��
HTK�и�����ȡ��������HCopy���ߣ�����wav��ʽ�������ļ�ת��Ϊ������������
ʸ���������ļ��������������£�
HCopy �CA �CD �CC hcopy.conf -S hcopy.scp
����hcopy.conf��һ�������ļ������ڶ�������ȡ�����еIJ����������ã�������ʾ��
hcopy.scpΪ����������Դ�ļ�������Ŀ���ļ��Ե��б�����ʽ���£�

����ģ�ͽṹ����
�ڱ��ĵ������У��������Ҫ��ģ��������Ԫ�����������رա�������ʼ������ֹͣ������sil��������ÿһ��������Ԫ��������һ����Ӧ������ģ������ģ����Ҫȷ��������ģ�ͽṹ����������
1��״̬����
2��ÿ��״̬�����������ʽ
3��״̬�����ת��ϵ
�ڱ��������Dz�����õĽṹ���ã�������ʾ��
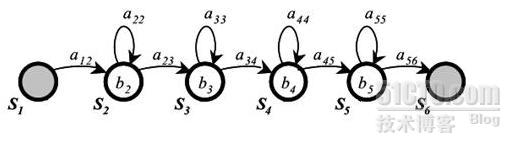
ģ�Ͱ���4���������״̬{S2,S3,S4,S5}����һ�������һ��״̬{S1,S6}�����������ֻ��Ϊ�˲������㡣ÿ��״̬���������b�� �öԽǷ�����Ļ�ϸ�˹�ֲ�������������
����ģ��ѵ��
 1. ģ�ͳ�ʼ��
1. ģ�ͳ�ʼ��
��ѵ����ʼ�����ģ�Ͳ������г�ʼ������ʼ���ǻ�Ӱ��ѵ���������ٶ���ȷ�ԡ�HTK�ṩ�����ֳ�ʼ�����ߣ�HInit��HCompv.
(1) ����HInit��ʼ��
HInit -A -D -T 1 -S trainlist.txt -M model/hmm0 \
-H model/proto/hmmfile -l label -L label_dir nameofhmm
���У�nameofhmm������ģ�͵����ƣ��硰��ʼ�������رա���hmmfile��һ����������ģ��ԭ�͵��ļ��������˽ṹ��ת�ƹ�ϵ������ά���ȣ�model/hmm0Ϊ��ʼ�����ɵij�ʼģ���ļ���
(2) ����HCompv��ʼ��
HCompv -A -D -T 1 -S trainlist.txt -M model/hmm0flat \
-H model/proto/hmmfile -f 0.01 nameofhmm
2. �����ع�
ģ�Ͳ����Ĺ��Ʋ���HRest���ߣ����øù������һ�ֲ��������¹��ƣ��������������£�
HRest -A -D -T 1 -S trainlist.txt -M model/hmmi -H vFloors \
-H model/hmmi-1/hmmfile -l label -L label.dir nameofhmm
���У�trainlist.txt�ļ�������������ѵ����mfcc�����ļ��б���label_dir�Ǵ�ű�ע�ļ�(.lab)��Ŀ¼��vFloors����HCompv���ɵ���С����ֵ���ļ���
����ѵ��������Ҫ������Σ�ͨ��5-10�ִΣ�ÿ�ε���ʱ��HRest�����������ݵ���Ȼֵ��
ʶ����������ʵ䶨��
��������һ��ʶ����������Ҫ�����ʶ���������������ɴ�ʶ������磬ʶ�����缴�������п���ʶ��Ĵʻ���ӡ���HTK�У�֧���û�дһ������EBNF���ʽ���ı��ļ���HParse���߿����Զ��Ը��ı��ļ����н�����������Ӧ��ʶ�������ļ���
���ڱ����е����ӣ�����������ı��ļ���gram.txt�����£�

���У������ű�ʾ����0����γ��֣������ű�ʾ0��1�γ��֡�
Ȼ���ͨ��HParse����ʶ�������ļ���net.slf��
HParse -A -D -T 1 gram.txt net.slf
���ɵ�ʶ����������ͼ��ʾ��
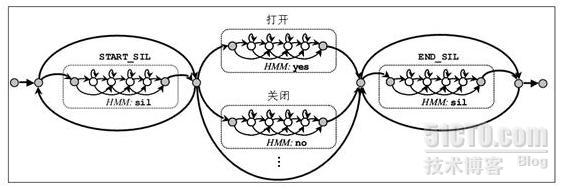
���˽���ʶ����ļ�������Ҫ�����ʵ䣬�ʵ���Ϊ�˽�����ʶ��Ľ��������ģ�������ĵ�Ԫ���ƽ�����Ӧ��ϵ�������ڱ�����������ֱ���Դ�Ϊ��Ԫ������ģ�ͣ���������Ĵʵ�ͷdz����ʵ䡰dict.txt��������ʾ��

ʶ����
ģ��ѵ����ɺ�Ϳ��Խ���ʶ��Ͳ����ˣ�
1. ����¼���ʶ����������硰input.sig��������HCopy����ת��ΪMFCC����ʸ���ļ�input.mfcc����ѵ��ʱ��ȡ����������ͬ����
2. ʶ����ͨ��Viterbi�㷨������ʸ���Ͻ��м��㣬��������ʵ�����ģ�ͽ���ƥ�䡣��һ����ͨ������HVite���еģ��������������£�
HVite -A -D -T 1 -H hmmdef.mmf -i reco.mlf -w net.slf \
dict.txt hmmlist.txt input.mfcc
���С�reco.mlf��Ϊ���ʶ�������ļ�����ʶ������ʽ������ʾ��
ʶ����
ģ��ѵ����ɺ�Ϳ��Խ���ʶ��Ͳ����ˣ�
1. ����¼���ʶ����������硰input.sig��������HCopy����ת��ΪMFCC����ʸ���ļ�input.mfcc����ѵ��ʱ��ȡ����������ͬ����
2. ʶ����ͨ��Viterbi�㷨������ʸ���Ͻ��м��㣬��������ʵ�����ģ�ͽ���ƥ�䡣��һ����ͨ������HVite���еģ��������������£�
HVite -A -D -T 1 -H hmmdef.mmf -i reco.mlf -w net.slf \
dict.txt hmmlist.txt input.mfcc
���С�reco.mlf��Ϊ���ʶ�������ļ�����ʶ������ʽ������ʾ��

3. ��ȻHTKҲ֧�ֲ���һ�ָ���Ȼ�ķ�ʽ����ʶ����ԣ���ֱ��¼������ʶ�𣬾������������£�
HVite -A -D -T 1 -C directin.conf -g -H hmmsdef.mmf \
-w net.slf dict.txt hmmlist.txt
���и�����������л���֡�READY[1]>������ʱ��ɽ�������¼�룬�����������¼������������ʶ�������ʾ����Ļ�ϣ� Ȼ����֡�READY[2]>��������һ��¼����ʶ��
����������ʶ��ʽ���ɳ����Զ�����������ȡ�������ļ�direction.conf�������¼����Ƶ��ʽ��������ȡ��������ĸ��������һ������ʾ�����£�

 ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



 ������ҫ�˺Ŷ�
������ҫ�˺Ŷ� MARVEL Strike
MARVEL Strike  2017��10������
2017��10������ �ȹپ�һƷ����
�ȹپ�һƷ����