����һЩɨ�����ļ���ɨ��������ļ������Ǻܹ淶����Щ��б����ô��ô���ܰ���Щɨ���ļ�����У���أ�����С�����Ҵ���������������ʶ����ô�� ��������OCR��������ɨ��У��������
��������OCR��������ɨ��У���̳�
����������Ҫ�ǽ��ܣ�����MICROTEKɨ���ǵ���������SCANWIZARD 5����������������OCR��������OCRʶ��Ĺ�����Ҫ�㡣
�Ƽ��Ĺ����������£�
1�� ɨ��ͼ���ļ���
������������ֱ��ʹ��SCANWIZARD 5������ע�⽫�����л���������ģʽ��ԭ���������ܱ����û����ɨ���ǹ���ʱ�ķֱ��ʡ�
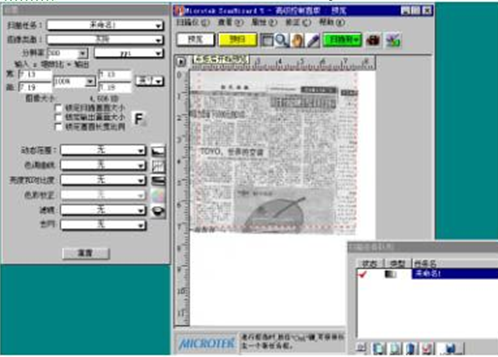
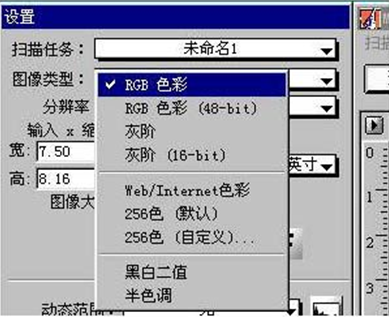
�Ƽ���ɨ��ֱ����趨��300DPI��ɫ��ģʽ�����ǡ�RGB��ɫ�����ߡ��ҽס���
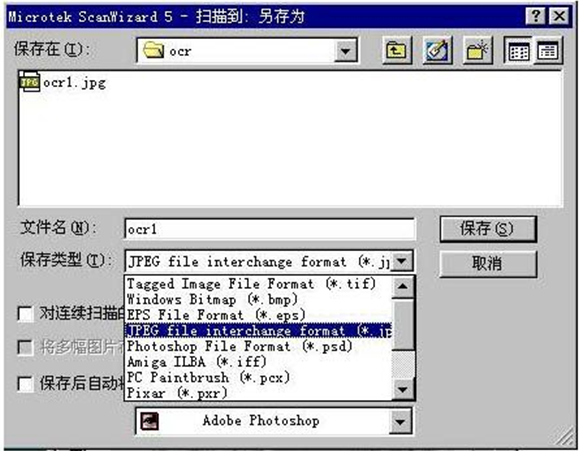
ѡ��ɨ�赽�����ļ���ʽ��TIF����JPG���߶����ԡ���ɨ����ļ������û�ȷ����Ŀ¼���档
2�� ���������Ŷ�ȡɨ��õ�ͼ���ļ���
3�� ��ʶ��ͼƬ��Ԥ������
�ⲿ�ֹ�������Ҫ��������бУ�����趨��ȷ��ʶ������
��бУ�����̣���ͼ��ʾ�����¹��������������һ�����ߡ�
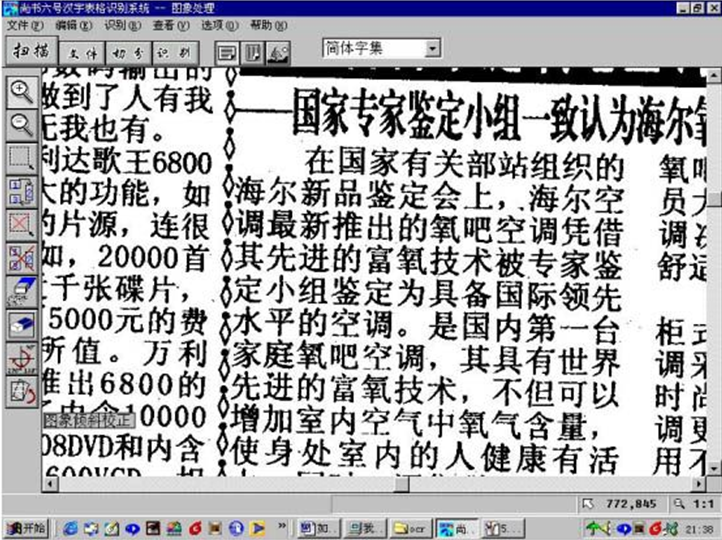
���¡�ͼ����бУ�������ߺ�������µĶԻ����ڣ�
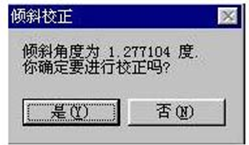
��ʱ���¡��ǡ�����ϵͳ����ͼƬ��ˮƽ����бУ�������������£�
ע�⣬�Զ���бУ�����ܣ�ֻ�ܶ�ԭ����+-2.8�ȵ���ǵ�У�������ԭ�����б�Ƕȴ���2.8�ȣ�ϵͳ�Ὠ���û�����ɨ�����������ʶ���ʡ�
�����ȷ�趨ʶ����������һ��ֵ���û�ע��ĵط���
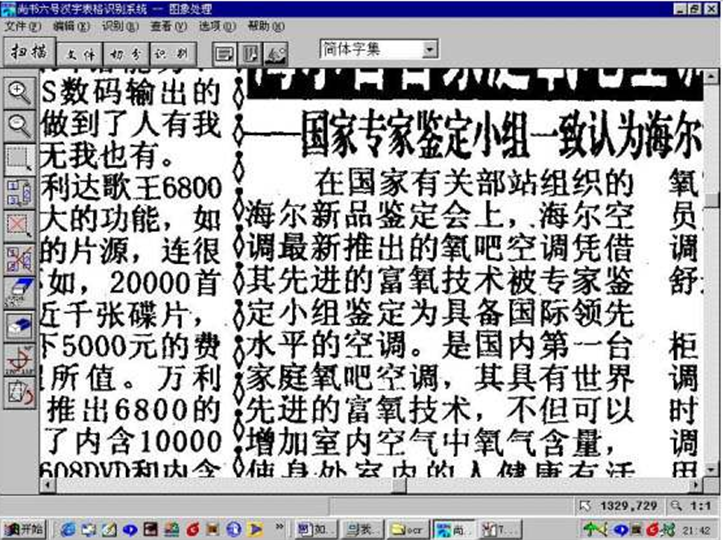
���µġ�������һ�ģ�ʵ���Ƿֳ�������Ŀ�������Ķ��ģ������������趨ʶ�������ʱ��ע����Ҫ������ص���ֳ�������Ҫ�趨����ʶ��������ͼ��ʾ��
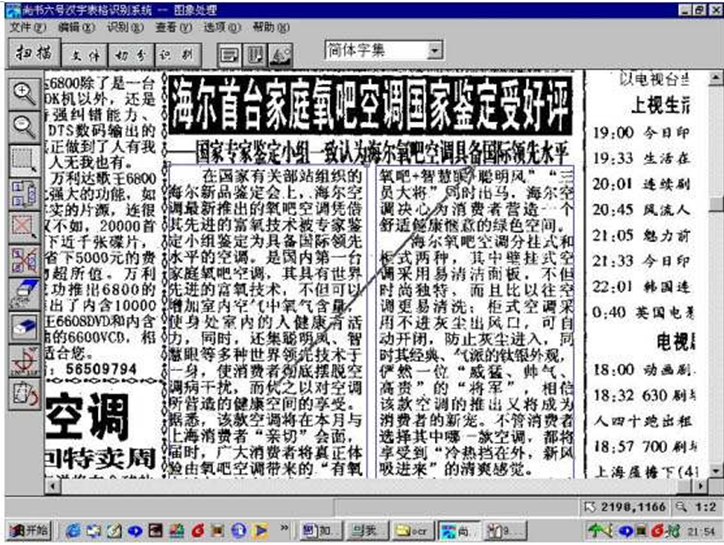
����һЩ���ָ�����м���ͼƬ��ʱ�����ǽ�������ƿ��ķ�ʽ������ʶ��������趨������ͼ��
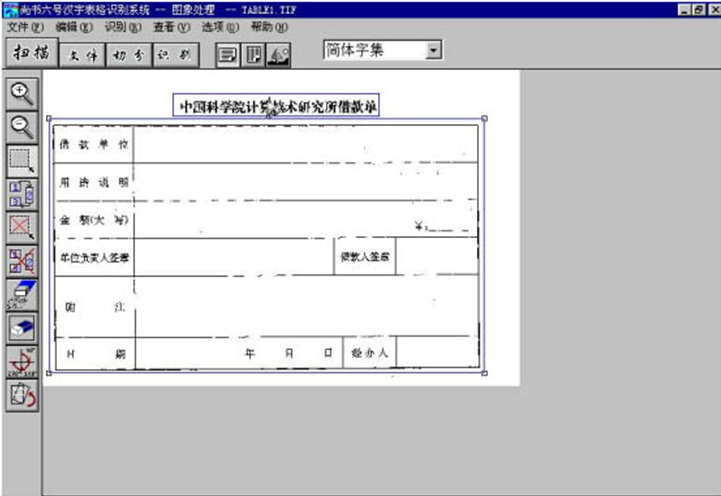
���ڱ������ͼƬ��Ϊ�˽�������Ҳ��ʶ���ȥ�����ǽ���������µ�ʶ�������趨���ص��DZ��ֱ���������ѡ��ͬʱ������Ϊһ�������Ŀ�ѡ����
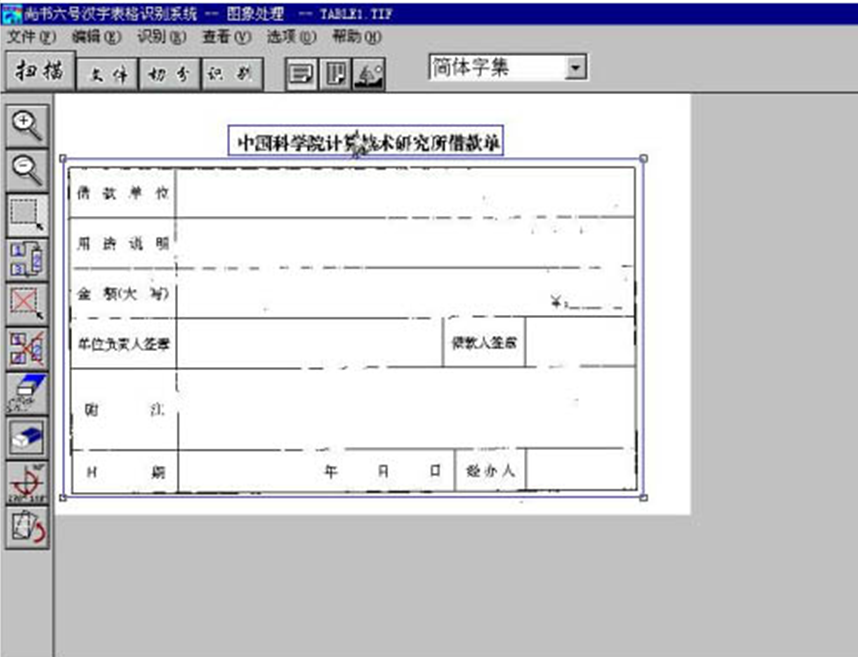
4�� ��ʼ����ʶ��
�ڿ�ʼ��ʶ�𡱵�ʱ��ע��ʶ����������趨ֵ�Ƿ���ȷ��Ĭ��ֵ���£�

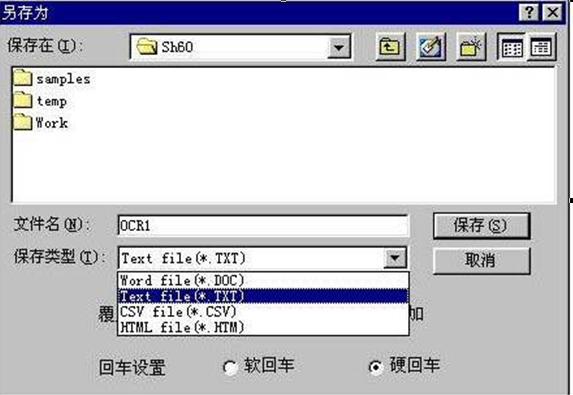
5�� ʶ��У����ɺ��̸�ʽ��ѡ���ļ���������������֣�����һ���ı���ʶ���û�ѡ��TXT��ʽ��
����DZ���ʶ��ʶ������ѡ��CSV����ʽ����EXCEL�ܹ���

 ����
���� 
 ����
���� 
 ����
����  ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
����  ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



 ������ҫ�˺Ŷ�
������ҫ�˺Ŷ� MARVEL Strike
MARVEL Strike  2017��10������
2017��10������ �ȹپ�һƷ����
�ȹپ�һƷ����