�����ߺ���һ��ܲ���������ʶ����������ô��ȷ��ȡͼƬ��������ֻ�����Ҫһ���ļ��ɵģ�ע��һ�㼼��,����Ч�ʻ��ǻ���ߵģ��������ҷ������������ߺ�����ʶ��������ȡ���ּ��ɡ�
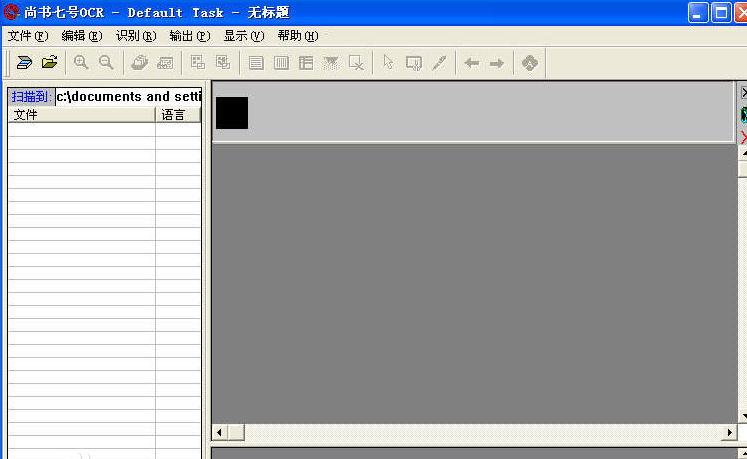
����ʹ�÷���:
1���������ߺ�,ѡ���ͼ�����õİ汾����ʶ��ĸ�ʽ��bmp��tif��jpg��
2��ѡ��ʼʶ���F8��ʶ��������ʾ�ڴ����ϲ����²���ʾ���������������к���Ϊ��ʶ�֣�����Ϊ����ʶ��
3��ѡ�����--��ָ����ʽ�ļ�����ʶ��������Ϊ��Ҫ�ĸ�ʽ��
ʶ��ǰӦע������⣺
1��ͼƬ����������ʶ��ʱ������Ӧȷ��Ҫʶ���ͼƬ�������粻��ʶ����Ҫ���´����������ᵼ�������������˷�ʱ�䡣�ұ��˾���������ࡣͼƬ�ֱ���Ӧ�Ըߣ����ۿ��о�ƫ����Ϊʶ�����е���ӵģ����ֺ͵�ɫ�Ա�Ҫ�ߣ�ͨ����˵�������ܿ�������ɣ���ɫ���һڻ�������Ӱ��ʶ������
2�������в�������״��ͼƬ�����֡�ʶ���ڽ��а������ʱ��ֻ�ܲ��÷����и��ͼƬ�д������ֻ��Ʋ�������״ʱ�����������ֺ���״���ֿ������ִ������ʶ�𡣴�ʱ���Ͽ�İ취����PS�У���ȡ��ͼƬ������ҳ���ɫ���ôֻ��ʽ�������Ϳ�ϣ����ؽ���Ч������ɫû��̫���ɣ����±���ͼƬ��
3������ͼ����б�������ߺ���Ҳ���Զ���бУ�����ֶ���бУ�����ߣ�����ʹ����У����ʶ���ʻ��ǵͺܶࡣ�����������鱾�����ܻ����һ�����ȣ���ʱ��֤�е����˶��뼴�ɡ�����������ʱӦ����߹�Ȼ�ʹͼ����������ȷ����������
�鱾ת����ɨ�衢���㣩����
1�����Խ���̯ƽ��һ�ν����߶�ɨ���������������ʡʱ�䡣����ͼƬʱ���ؼ�������ʱҪ�õ������ߺŵķ��������ˡ�ֱ��������ڴ�ͼ������ק���ɳ���ѡ�ֳ����������������������Ͻǵı�ž���ʶ����������˳�����Ὣ�Զ����ձ��˳�����з���������������һ��
2���ֶ������ɽ������ͼ����ʶ������⡣�ڽ���ʶ����Կ�����������������ʱ������ͼ������ԭ���Զ�����������Ч����ֻ�Ǻ�С��һ���֡���ʱ����ctrl+delȡ���������������������ק��������Ҫʶ��ķ�Χ�����½���ʶ�𡣵�ͼƬ�������ⲻ��ʱ������취��Ч��
��ʱ����������������ͼƬ��������Ť�����أ���ʹ��PSҲ�������á��ɳ����ֶ���������ּ�����ÿһ������һ�л������������֣���������ÿ��������˵�����������ķ�Χ��������Լ�С�������ʶ���ʡ�
3��ʹ������ʶ���ܡ������ߺſ���һ����ʶ�����ͼƬ������ʵ��Ӧ���У�����ʶ���˹��࣬������ʱ���ʶ���������ִ���ʱ������
4������ʶ��ͼ��ʱ�������ļ�ҲҪ���Ѵ���ʱ�䡣��ʵ�ϣ������ߺ���ʶ���ļ���ͬʱ������ͼƬ�����ļ��������ı��ĵ���������ͼƬ������ͬ����ˣ���������ر���Ҫ�����Բ����ٱ�����������
����ʶ����������һ���֣����Խ�����ͼ���б�ȫѡ��ctrl+A������ѡ�����--��ָ����ʽ�ļ�������ǰ����ʶ�����ݰ���ͼƬ����˳����һ���ļ��С�
��ʹ�õ������ߺŲ��ܼ��䱣��·����ÿ��ѡ��ʱ������Ĭ�ϴ���װĿ¼�µġ�outout���ļ��У�����ÿ�ζ�ѡ��·���������ȱ��������Ȼ��һ��ת���ļ���
5������뱣���ļ��е�ͼƬ����������ʱѡ��RTF��ʽ������word�����Կ�����ʽ��ȫ��ȷ�����ֺ�ͼƬ�ˡ�
6�����鱾��ҳ����ļ����������ǵ�ѡ��������������ժҪ����������Ϊ�������ˣ������������������ַ�ʱ�ں��ӡ�
7����һ��ͼ����ȫ��ʶ��ʱ���������������Ȼ�Աȶȣ���ʱ��ֻ����ôһ��㣬��Ҳ�����㹤����
8�������ļ������͡�������һ������ʱ���������л���Ӧ�������͵İ�Ŧ�ᰴ�¡������к������������֣����������������֣���ͼƬ������ȼ������ͣ�һ������¿����Զ�ʶ�����ͣ����ֶ�����ʱһ��Ҫѡ����Ӧ�����ͣ������ʶ���ʡ�
���������������������ԣ�ɨ��Ļ����Ż�������⣬����ܲ���Ļ�����û��Dz�ɡ�

 ����
���� 
 ����
���� 
 ����
����  ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
����  ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����



 ������ҫ�˺Ŷ�
������ҫ�˺Ŷ� MARVEL Strike
MARVEL Strike  2017��10������
2017��10������ �ȹپ�һƷ����
�ȹپ�һƷ����