1��ORACLE �Ľ��������մ��ҵ����˳���� FROM �Ӿ��еı�������� FROM �Ӿ���д�����ı�(������ driving table)�������ȴ�������FROM �Ӿ��а��������������£������ѡ���¼�������ٵı���Ϊ��������
���磺
��ceshi_xiao��969����¼��emp_xiao��14����¼��
select count(*) from emp_xiao, ceshi_xiao;����������
select count(*) from ceshi_xiao, emp_xiao;���������� 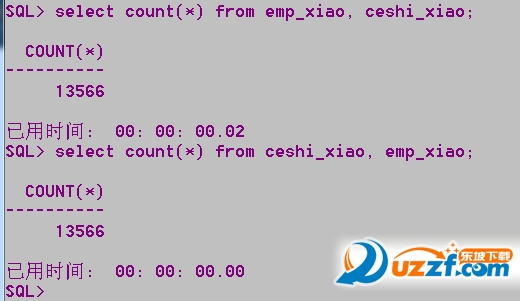
ע�⣺��������ceshi_xiao����¼̫�ٲ�����ԣ����Ѿ��ܿ�����𡣵�����¼�ϰ�����ʱ���ò������Ŵ�
2��ORACLE �������¶��ϵ�˳����� WHERE �Ӿ䡣
�������ԭ������֮������ӱ���д������ WHERE ����֮ǰ�� ��Щ���Թ��˵����������¼����������д�� WHERE �Ӿ��ĩβ��
���磺
SELECT ��
FROM EMP E
WHERE SAL > 50000
AND JOB = ��MANAGER'
AND 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO); (��Ч��ִ��ʱ�� 156.3��)
SELECT ��
FROM EMP E
WHERE 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO)
AND SAL > 50000
AND JOB = ��MANAGER';(��Ч,ִ��ʱ�� 10.6��)
ע�⣺�ڽ��ж������ʱ������ Where ���ѵ������Ľ������С�������þۺϺ������ܽ��������������������������ʹ�������������С����
3�����ٶԱ��IJ�ѯ��
�ں����Ӳ�ѯ�� SQL����У�Ҫ�ر�ע����ٶԱ��IJ�ѯ��
4����EXISTS���IN��
��������ڻ������IJ�ѯ�У�Ϊ������һ��������������Ҫ����һ�����������ӡ����� ������£� ʹ�� EXISTS(�� NOT EXISTS)ͨ������߲�ѯ��Ч�ʡ�ʹ�� exists ������ IN ��Ϊ Exists ֻ����еĴ��ڣ��� in ���ʵ��ֵ��
���磺
SELECT *
FROM EMP (������)
WHERE EMPNO > 0
AND DEPTNO IN (SELECT DEPTNO
FROM DEPT
WHERE LOC = ��MELB')������
SELECT *
FROM EMP (������)
WHERE EMPNO > 0
AND EXISTS (SELECT ��X'
FROM DEPT
WHERE DEPT.DEPTNO = EMP.DEPTNO
AND LOC = ��MELB') ������
�� IN �� SQL �������DZȽϵͣ�ԭ���ǣ������� IN �� SQL ��� ORACLE ������ͼ����ת���ɶ���������ӣ����ת�����ɹ�����ִ�� IN������Ӳ�ѯ���ٲ�ѯ���ı���¼���ת���ɹ���ת���ɶ���������ӡ���� ��������ô���� IN �� SQL ������Ƕ��� һ��ת���Ĺ��̡������ҵ���ܼ���SQL���о���������IN��������
5����EXISTS�滻DISTINCT��
���ύһ������һ�Զ����Ϣ(���粿�ű���Ա��)�IJ�ѯʱ��������SELECT �Ӿ� ��ʹ�� DISTINCT. һ����Կ����� EXIST �滻��
���磺SELECT DISTINCT DEPT_NO,DEPT_N
FROM DEPT D,EMP E
WHERE D.DEPT_NO = E.DEPT_NO������
SELECT DEPT_NO,DEPT_NAME
FROM DEPT D
WHERE EXISTS ( SELECT ��X'
FROM EMP E
WHERE E.DEPT_NO = D.DEPT_NO);������
6���ñ������滻EXISTS��
ͨ����˵ �����ñ����ӵķ�ʽ�� EXISTS ����Ч�ʡ�
���磺
SELECT ENAME
FROM EMP E
WHERE EXISTS (SELECT ��X'
FROM DEPT
WHERE DEPT_NO = E.DEPT_NO
AND DEPT_CAT = ��A');
Ϊ�����Ч�ʡ���дΪ��
SELECT ENAME
FROM DEPT D,EMP E
WHERE E.DEPT_NO = D.DEPT_NO
AND DEPT_CAT = ��A' ;
7����������������ʹ�ü��㡣
WHERE �Ӿ��У�����������Ǻ�����һ���֡��Ż�������ʹ��������ʹ��ȫ��ɨ�衣����һ���dz�ʵ�õĹ���������μǡ�
���磺
SELECT ��
FROM DEPT
WHERE SAL * 12 > 25000; ������
SELECT ��
FROM DEPT
WHERE SAL > 25000/12; ������
8����������������ʹ��NOT��
ͨ��������Ҫ��������������ʹ�� NOT��NOT ������ں�����������ʹ�ú�����ͬ ��Ӱ�졣��ORACLE��������NOT�����ͻ�ֹͣʹ������ת��ִ��ȫ��ɨ�衣
9����ʹ��<>��!=��~=��^=��������
�����ڲ���������Զ�����õ������ģ���˶����Ĵ���ֻ�����ȫ��ɨ�衣
a <> 0 ==> a > 0 or a < 0
10����>=���>��
SELECT *
FROM EMP
WHERE DEPTNO >3������
SELECT *
FROM EMP
WHERE DEPTNO >=4������
���ߵ��������ڣ� ǰ�� DBMS��ֱ��������һ�� DEPT ���� 4�ļ�¼�����߽����ȶ�λ�� DEPTNO=3�ļ�¼������ǰɨ�赽��һ�� DEPT ���� 3�ļ�¼��
11����ʹ��like ��������
���� ��Ҫ�õ� LIKE ���˵�SQL��䣬��ȫ������ instr ���棬�����ٶȽ�������ߡ�
12����(UNION)UNION ALL�滻OR (������������)��
ͨ������£� �� UNION�滻 WHERE �Ӿ��е� OR�����Ϻõ�Ч������������ʹ�� OR�����ȫ��ɨ�衣ע�⣬ ���Ϲ���ֻ��Զ����������Ч�� ����� columnû�б������� ��ѯЧ�ʿ��ܻ���Ϊ��û��ѡ�� OR�����͡�
�������Ҫ�� OR�� �Ǿ���Ҫ���ؼ�¼���ٵ�������д����ǰ�档ע��, ���Ϲ���ֻ��Զ����������Ч. �����columnû�б�����, ��ѯЧ�ʿ��ܻ���Ϊ��û��ѡ��OR�����͡�
13���Ż�GROUP BY��
��� GROUP BY ����Ч�ʣ� ����ͨ��������Ҫ�ļ�¼�� GROUP BY ֮ǰ���˵�������������ѯ������ͬ������ڶ������ԾͿ������ࡣ
���磺
SELECT JOB �� AVG(SAL)
FROM EMP
GROUP by JOB
HAVING JOB = ��PRESIDENT'
OR JOB = ��MANAGER'������
SELECT JOB �� AVG(SAL)
FROM EMP
WHERE JOB = ��PRESIDENT'
OR JOB = ��MANAGER'GROUP by JOB������
ʹ�� where ������ having ��where�����ڹ����еģ���having������������ģ���Ϊ�б������having ���ܹ����飬���Ծ����� WHERE ���ˡ�
14������ı������е����͡�
���Ƚϲ�ͬ�������͵�����ʱ, ORACLE�Զ����н��м�����ת����
15��SQL��д��Ӱ�졣
ͬһ����ͬһ���ܲ�ͬд��SQL��Ӱ�졣
���磺
��һ��SQL��A����Աд��Ϊselect * from zl_yhjbqk
B����Աд��Ϊselect * from dlyx.zl_yhjbqk�����������ߵ�ǰ��
C����Աд��Ϊselect * from DLYX.ZLYHJBQK����д������
D����Աд��Ϊselect * from DLYX.ZLYHJBQK���м���˿ո�
�ĸ�SQL��ORACLE��������֮������Ľ����ִ�е�ʱ����һ���ģ����Ǵ�ORACLE�����ڴ�SGA��ԭ�������Եó�ORACLE��ÿ��SQL����������һ�η���������ռ�ù����ڴ棬�����SQL���ַ�������ʽд����ȫ��ͬ��ORACLEֻ�����һ�Σ������ڴ�Ҳֻ������һ�εķ���������ⲻ�����Լ��ٷ���SQL��ʱ�䣬���ҿ��Լ��ٹ����ڴ��ظ�����Ϣ��ORACLEҲ����ȷͳ��SQL��ִ��Ƶ�ʡ�
�ܽ
1).Ӧ���������� where �Ӿ��ж��ֶν��� null ֵ�жϣ��������������ʹ������������ȫ��ɨ�衣
2).Ӧ���������� where �Ӿ���ʹ��!=��<>�������������������ʹ������������ȫ��ɨ�衣
3).Ӧ���������� where �Ӿ���ʹ�� or �������������������������ʹ������������ȫ��ɨ�衣
4).in �� not in ҲҪ���ã�����ᵼ��ȫ��ɨ�衣
5).��ʹ�������ֶ���Ϊ����ʱ������������Ǹ�����������ô����ʹ�õ��������еĵ�һ���ֶ���Ϊ����ʱ���ܱ�֤ϵͳʹ�ø���������������������ᱻʹ�ã�����Ӧ�����ܵ����ֶ�˳��������˳����һ�¡�
6).�κεط�����Ҫʹ�� select * from t ���þ�����ֶ��б����桰*������Ҫ�����ò������κ��ֶΡ�
 ����
���� 
 ����
���� 
 ����
����  ����
����  ����
����  ����
���� 

 ����
����  ����
����  ����
����  ����
����  ����
����  ����
���� 
 ����
����  ����
����  ����
����  ����
����  ����
����  ϲ��
ϲ��  ��
�� �ѹ�
�ѹ� ��
�� ��
�� ����
����






 ������ҫ�˺Ŷ�
������ҫ�˺Ŷ� MARVEL Strike
MARVEL Strike  2017��10������
2017��10������ �ȹپ�һƷ����
�ȹپ�һƷ����