











SQL语言基本上独立于数据库本身、使用的机器、网络、操作系统,基于SQL的DBMS产品可以运行在从个人机、工作站到基于局域网、小型机和大型机的各种计算机系统上,具有良好的可移植性。
在实际的软件项目中,如果系统中需要存储的数据量比较大,需要设计的表比较多,表与表之间的关系比较复杂,那我们就需要进行规范的数据库设置。如果不经过数据库的设计,我们构建的数据库不合理、不恰当,那么数据库的维护、运行效率会有很大的问题。这将直接影响到项目的运行性和可靠性。
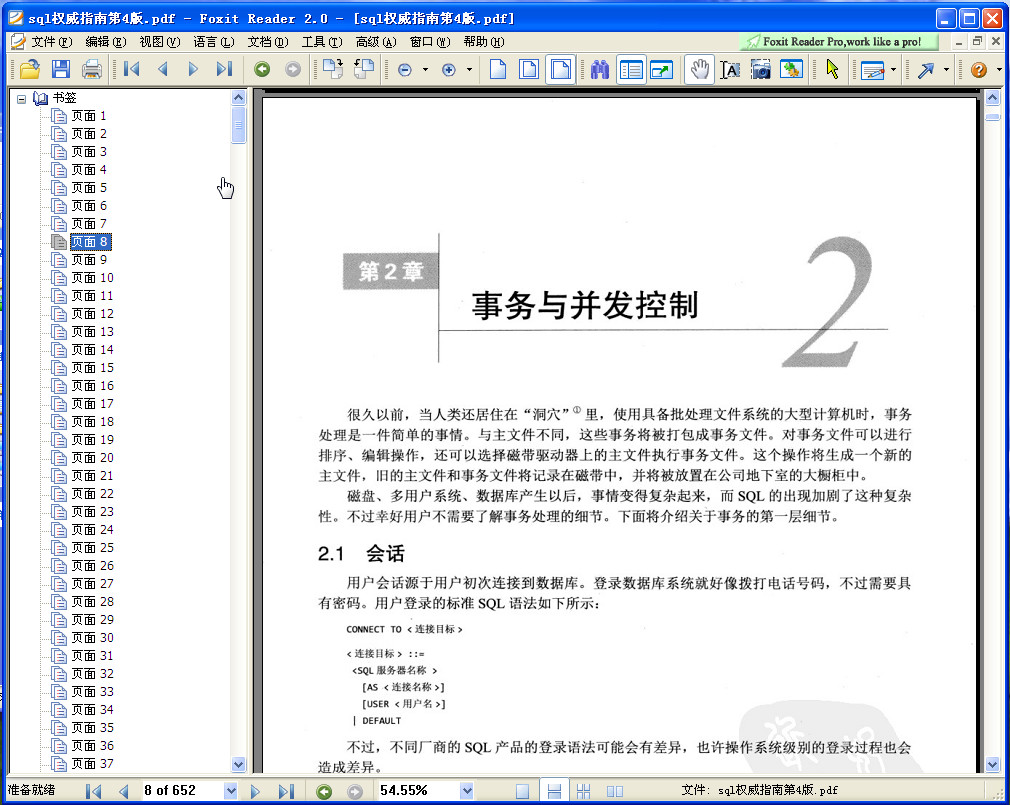
sql权威指南 第4版目录
第1章 数据库与文件系统
1.1 实体表
1.2 关系表
1.3 行与记录
1.4 列与字段
1.5 模式对象
1.6 CREATE SCHEMA语句
第2章 事务与并发控制
2.1 会话
2.2 事务与ACID
2.2.1 原子性
2.2.2 一致性
2.2.3 隔离性
2.2.4 持久性
2.3 并发控制
2.3.1 三种现象
2.3.2 隔离级别
2.4 保守式并发控制
2.5 快照隔离与乐观式并发
2.6 逻辑并发控制
2.7 死锁与活锁
第3章 数据库模式对象
3.1 CREATE SCHEMA语句
3.2 CREATE PROCEDURE、CREATE FUNCTION以及CREATE TRIGGER语句
3.3 CREATE DOMAIN语句
3.4 创建序列
3.5 创建断言
3.5.1 为模式级约束使用视图
3.5.2 为约束使用主键和断言
3.6 字符集相关结构
3.6.1 创建字符集
3.6.2 创建排序规则
3.6.3 创建翻译
第4章 定位数据和特殊数值
4.1 显式的物理定位器
4.1.1 ROWID和物理磁盘地址
4.1.2 标识列
4.2 生成的标识符
4.2.1 GUID
4.2.2 UUID
4.3 序列生成函数
4.4 预分配值
4.5 特殊序列
4.5.1 Series表
4.5.2 素数
4.5.3 随机顺序值
4.5.4 其他序列
第5章 基础表和相关元素
5.1 CREATE TABLE语句
5.1.1 列约束
5.1.2 DEFAULT子句
5.1.3 NOT NULL约束
5.1.4 CHECK()约束
5.1.5 UNIQUE以及PRIMARY KEY约束
5.1.6 REFERENCES子句
5.2 嵌套UNIQUE约束
5.2.1 重叠键
5.2.2 单列唯一性与多列唯一性
5.3 CREATE ASSERTION约束
5.4 临时表
5.5 表操作
5.5.1 DROP TABLE <表名>
5.5.2 ALTER TABLE
5.6 避免属性分割
5.6.1 表级属性分割
5.6.2 行级属性分割
5.7 在DDL中表现类层次关系
5.8 显式物理定位器
5.9 自增列
5.9.1 ROWID与物理磁盘地址
5.9.2 标识列
5.9.3 对比标识列和序列
5.10 生成标识符
5.10.1 行业标准的唯一标识符
5.10.2 国防部的唯一标识符
5.10.3 序列生成函数
5.10.4 唯一值生成器
5.10.5 验证源
5.11 关于重复行
5.12 其他模式对象
5.13 临时表
5.14 CREATE DOMAIN语句
5.15 CREATE TRIGGER语句
5.16 CREATE PROCEDURE语句
5.17 DECLARE CURSOR语句
5.17.1 如何使用游标
5.17.2 位置更新及删除语句
第6章 过程式、半过程式以及声明式编程
6.1 软件工程基本原理
6.2 内聚性
6.3 耦合度
6.4 大跨越
6.4.1 一个常见的错误
6.4.2 一处改进
6.5 重写技巧
6.5.1 数据表和生成器代码
6.5.2 用计算替代查找
6.5.3 斐波那契数列
6.6 谓词函数
6.7 过程化分解和逻辑分解
6.7.1 过程式分解方案
6.7.2 逻辑分解方案
第7章 过程式结构
7.1 创建过程
7.2 创建触发器
7.3 游标
7.3.1 DECLARE CURSOR语句
7.3.2 ORDER BY子句
7.3.3 OPEN语句
7.3.4 FETCH语句
7.3.5 CLOSE语句
7.3.6 DEALLOCATE语句
7.3.7 如何使用游标
7.3.8 位置更新及删除语句
7.4 序列
7.5 生成列
7.6 表函数
第8章 辅助表
8.1 序列表
8.1.1 对列表进行枚举
8.1.2 将序列映射为循环
8.1.3 取代迭代循环
8.2 查找辅助表
8.2.1 简单转换辅助表
8.2.2 多转换值辅助表
8.2.3 多参数辅助表
8.2.4 范围辅助表
8.2.5 层次结构辅助表
8.2.6 “一个真正的查找表”
8.3 辅助函数表
8.3.1 用辅助表求反函数
8.3.2 用辅助函数表进行插值
8.4 全局常量表
8.4.1 预分配值
8.4.2 素数
8.4.3 斐波那契数列
8.4.4 随机顺序值
8.5 把过程代码转换成表时的注意事项
第9章 规范化
9.1 函数依赖和多值依赖
9.2 第一范式(1NF)
9.3 第二范式(2NF)
9.4 第三范式(3NF)
9.5 基本关键字范式(EKNF)
9.6 Boyce-Codd范式(BCNF)
9.7 第四范式(4NF)
9.8 第五范式(5NF)
9.9 域-键范式(DKNF)
9.10 规范化的实用技巧
9.11 键类型
9.11.1 自然键
9.11.2 人工键
9.11.3 对外暴露的物理定位器
9.12 非规范化的实用技巧
第10章 SQL的数值数据
10.1 数值类型
10.2 数值类型的转换
10.2.1 数值的舍入和截断
10.2.2 CAST()函数
10.3 四则运算函数
10.4 算术运算和NULL
10.5 值与NULL的相互转换
10.5.1 NULLIF()函数
10.5.2 COALESCE()函数
10.6 数学函数
10.6.1 数学运算符
10.6.2 指数函数
10.6.3 标量函数
10.6.4 将数值转换为文字
10.7 唯一值生成器
10.7.1 存有间隙的序列
10.7.2 预分配数值
10.8 IP地址
10.8.1 CHAR(39)存储
10.8.2 二进制存储
10.8.3 使用多个单独的SMALLINT
第11章 SQL中的时间数据类型
11.1 关于日历标准的说明
11.2 SQL时间数据类型
11.2.1 时间的内部表示
11.2.2 日期格式标准
11.2.3 处理时间戳
11.2.4 处理时间
11.2.5 时区和夏令时
11.3 INTERVAL数据类型
11.4 时间算术
11.5 时间数据模型的特性
11.5.1 为持续时间建模
11.5.2 持续时间之间的关系
第12章 字符数据类型
12.1 SQL字符串问题
12.1.1 字符串相等问题
12.1.2 字符串排序问题
12.1.3 字符串分组问题
12.2 标准字符串函数
12.3 常见的厂商扩展
12.4 Cutter表
12.5 嵌套替换
第13章 NULL:SQL中的缺失数据
13.1 空表和缺失表
13.2 列中的缺失值
13.3 上下文和缺失值
13.4 比较NULL
13.5 NULL和逻辑
13.5.1 子查询谓词中的NULL
13.5.2 逻辑值谓词
13.6 算术中的NULL值
13.7 函数中的NULL值
13.8 NULL和宿主语言
13.9 NULL的设计忠告
13.10 关于多NULL值的说明
第14章 多列数据元素
14.1 距离函数
14.2 在SQL中存储IPv4地址
14.2.1 使用单个VARCHAR(15)列表示IPv4地址
14.2.2 使用一个INTEGER列表示IPv4地址
14.2.3 使用四个SMALLINT列表示IPv4地址
14.3 在SQL中存储IPv6地址
14.4 货币与其他单位的转换
14.5 社会安全号
14.6 有理数
第15章 表操作
15.1 DELETE FROM语句
15.1.1 DELETE FROM子句
15.1.2 WHERE子句
15.1.3 根据辅助表中的数据执行删除
15.1.4 在相同表内进行删除
15.1.5 不用声明引用完整性在多个表中进行删除
15.2 INSERT INTO语句
15.2.1 INSERT INTO子句
15.2.2 插入的性质
15.2.3 批量装载和卸载实用程序
15.3 UPDATE语句
15.3.1 UPDATE子句
15.3.2 WHERE子句
15.3.3 SET子句
15.3.4 利用第二张表进行更新
15.3.5 在UPDATE中使用CASE表达式
15.4 常见厂商扩展的缺陷说明
15.5 MERGE语句
第16章 比较或theta操作
16.1 数据类型转换
16.1.1 日期显示格式
16.1.2 其他显示格式
16.2 SQL中的行比较
16.3 IS [NOT] DISTINCT FROM操作符
第17章 值化谓词
17.1 IS NULL谓词
17.2 IS [NOT] {TRUE | FALSE | UNKNOWN}谓词
17.3 IS [NOT] NORMALIZED谓词
第18章 CASE表达式
18.1 CASE表达式
18.1.1 COALESCE()和NULLIF()函数
18.1.2 带GROUP BY的CASE表达式
18.1.3 CASE、CHECK()子句和逻辑蕴涵
18.2 子查询表达式和常量
18.3 Rozenshtein特征函数
第19章 LIKE与SIMILAR TO谓词
19.1 使用模式的技巧
19.2 NULL值和空字符串的谓词结果
19.3 LIKE并不是相等
19.4 用联结消除LIKE谓词
19.5 CASE表达式和LIKE搜索条件
19.6 SIMILAR TO谓词
19.7 字符串的有关技巧
19.7.1 字符串的字符内容
19.7.2 搜索与声明一个串
19.7.3 创建字符串中的索引
第20章 BETWEEN和OVERLAPS谓词
20.1 BETWEEN谓词
20.1.1 NULL值的结果
20.1.2 空集的结果
20.1.3 程序设计技巧
20.2 OVERLAPS谓词
第21章 [NOT] IN()谓词
21.1 优化IN()谓词
21.2 用IN()谓词替换OR
21.3 NULL和IN()谓词
21.4 IN()谓词和引用约束
21.5 IN()谓词和标量查询
第22章 EXISTS()谓词
22.1 EXISTS和NULL
22.2 EXISTS和INNER JOIN
22.3 NOT EXISTS和OUTER JOIN
22.4 EXISTS()和量词
22.5 EXISTS()和引用约束
22.6 EXISTS和三值逻辑
第23章 量化子查询谓词
23.1 标量子查询比较
23.2 量词和缺失数据
23.3 ALL谓词和极值函数
23.4 UNIQUE谓词
23.5 DISTINCT谓词
第24章 简单SELECT语句
24.1 SELECT语句执行顺序
24.2 单级SELECT语句
第25章 高级SELECT语句
25.1 关联子查询
25.2 嵌入的INNER JOIN
25.3 OUTER JOIN
25.3.1 OUTER JOIN的一些历史
25.3.2 NULL和OUTER JOIN
25.3.3 NATURAL JOIN与搜索式OUTER JOIN
25.3.4 OUTER JOIN自联结
25.3.5 两次或多次OUTER JOIN
25.3.6 OUTER JOIN和聚合函数
25.3.7 FULL OUTER JOIN
25.4 UNION JOIN操作符
25.5 标量SELECT表达式
25.6 旧JOIN语法与新JOIN语法
25.7 受约束的JOIN
25.7.1 库存和订单
25.7.2 稳定的婚姻
25.7.3 将球装入盒中
25.8 Codd博士的T联结
25.8.1 Stobbs方案
25.8.2 Pieere方案
25.8.3 参考文献
第26章 虚拟表:视图、派生表、CTE及MQT
26.1 查询中的视图
26.2 可更新视图和只读视图
26.3 视图的类型
26.3.1 单表投影和限制
26.3.2 计算列
26.3.3 转换列
26.3.4 分组视图
26.3.5 联结视图
26.3.6 视图的联结
26.3.7 嵌套视图
26.4 数据库引擎如何处理视图
26.4.1 视图列列表
26.4.2 视图物化
26.4.3 内嵌文本扩展
26.4.4 指针结构
26.4.5 索引和视图
26.5 WITH CHECK OPTION子句
26.6 删除视图
26.7 视图与临时表的使用提示
26.7.1 使用视图
26.7.2 使用临时表
26.7.3 用视图扁平化表
26.8 使用派生表
26.8.1 FROM子句中的派生表
26.8.2 包含VALUES构造器的派生表
26.9 公用表表达式
26.10 递归公用表表达式
26.10.1 简单增量
26.10.2 简单树遍历
26.11 物化查询表
第27章 在查询中分区数据
27.1 覆盖和分区
27.1.1 按范围分区
27.1.2 单列范围表
27.1.3 用函数进行分区
27.1.4 按顺序分区
27.1.5 使用窗口函数进行分区
27.2 关系除法
27.2.1 带余除法
27.2.2 精确除法
27.2.3 性能说明
27.2.4 Todd的除法
27.2.5 带JOIN的除法
27.2.6 用集合操作符进行除法
27.3 Romley除法
27.4 RDBMS中的布尔表达式
27.5 FIFO和LIFO子集
第28章 分组操作
28.1 GROUP BY子句
28.2 GROUP BY和HAVING
28.3 多层次聚合
28.3.1 多级聚合的分组视图
28.3.2 多层次聚合的子查询表达式
28.3.3 多层聚合的CASE表达式
28.4 在计算列上分组
28.5 成对分组
28.6 排序和GROUP BY
第29章 简单聚合函数
29.1 COUNT()函数
29.2 SUM()函数
29.3 AVG()函数
29.3.1 空组的平均数
29.3.2 多个列上的平均值
29.4 极值函数
29.4.1 简单的极值函数
29.4.2 广义极值函数
29.4.3 多条件极值函数
29.4.4 GREATEST()和LEAST()函数
29.5 LIST()聚合函数
29.5.1 使用递归CTE的LIST聚合函数
29.5.2 交叉表的LIST()函数
29.6 PRD()聚合函数
29.6.1 通过表达式实现PRD()函数
29.6.2 通过对数实现PRD()聚合函数
29.7 位运算符聚合函数
29.7.1 OR位运算符聚合函数
29.7.2 AND位运算符聚合函数
第30章 高级分组、窗口聚合以及SQL中的OLAP
30.1 星模式
30.2 GROUPING操作符
30.2.1 GROUP BY GROUPING SET
30.2.2 ROLLUP
30.2.3 CUBE
30.2.4 SQL的OLAP示例
30.3 窗口子句
30.3.1 PARTITION BY子句
30.3.2 ORDER BY子句
30.3.3 窗口帧子句
30.4 窗口化聚合函数
30.5 序号函数
30.5.1 行号
30.5.2 RANK()和DENSE_RANK()
30.5.3 PERCENT_RANK()和CUME_DIST()
30.5.4 一些示例
30.6 厂商扩展
30.6.1 LEAD和LAG函数
30.6.2 FIRST和LAST函数
30.7 一点历史知识
第31章 SQL中的描述性统计
31.1 众数
31.2 AVG()函数
31.3 中值
31.3.1 中值编程问题
31.3.2 Celko第一中值
31.3.3 Date第二中值
31.3.4 Murchison中值
31.3.5 Celko第二中值
31.3.6 Vaughan提出的应用视图的中值
31.3.7 使用特征函数的中值
31.3.8 Celko第三中值
31.3.9 Ken Henderson的中值
31.3.10 OLAP中值
31.4 方差和标准偏差
31.5 平均偏差
31.6 累积统计
31.6.1 运行差分
31.6.2 累积百分比
31.6.3 序号函数
31.6.4 五分位数和相关统计
31.7 交叉表
31.7.1 通过交叉联结建立交叉表
31.7.2 通过外联结建立交叉表
31.7.3 通过子查询建立交叉表
31.7.4 使用CASE表达式建立交叉表
31.8 调和平均数和几何平均数
31.9 SQL中的多变量描述统计数据
31.9.1 协方差
31.9.2 皮尔森相关系数r
31.9.3 多变量描述统计中的NULL值
31.10 SQL:2006中的统计函数
31.10.1 方差、标准偏差以及描述统计
31.10.2 相关性
31.10.3 分布函数
第32章 子序列、区域、顺串、间隙及岛屿
32.1 查找尺寸为n的子区域
32.2 为区域编号
32.3 查找最大尺寸的区域
32.4 界限查询
32.5 顺串和序列查询
32.6 数列的求和
32.7 交换和平移列表值
32.8 压缩一列数值
32.9 折叠一列数值
32.10 覆盖
第33章 SQL中的矩阵
33.1 通过命名列进行访问的数组
33.2 通过下标列进行访问的数组
33.3 SQL的矩阵操作
33.3.1 矩阵等式
33.3.2 矩阵加法
33.3.3 矩阵乘法
33.3.4 矩阵转置
33.3.5 行排序及列排序
33.3.6 其他矩阵操作
33.4 将表扁平化为数组
33.5 比较表格式中的数组
第34章 集合操作
34.1 UNION和UNION ALL
34.1.1 执行顺序
34.1.2 混合使用UNION和UNION ALL操作符
34.1.3 对同一表中的列执行UNION操作
34.2 INTERSECT和EXCEPT
34.2.1 没有NULL值和重复行时的INTERSECT和EXCEPT操作
34.2.2 存在NULL值和重复行时的INTERSECT和EXCEPT操作
34.3 关于ALL和SELECT DISTINCT的一个说明
34.4 相等子集和真子集
第35章 子集
35.1 表中的每个第n项
35.2 从表中选取随机行
35.3 CONTAINS操作符
35.3.1 真子集操作符
35.3.2 表的相等操作
35.4 序列间隙
35.5 重叠区间的覆盖问题
35.6 选取有代表性的子集
第36章 SQL中的树和层次结构
36.1 邻接列表模型
36.1.1 复杂约束
36.1.2 查询的过程遍历
36.1.3 更改表
36.2 路径枚举模型
36.2.1 查找子树和节点
36.2.2 找出层次和后代
36.2.3 删除节点和子树
36.2.4 完整性约束
36.3 层次结构的嵌套集合模型
36.3.1 计数特性
36.3.2 包含特性
36.3.3 下级节点
36.3.4 层次聚合
36.3.5 删除节点和子树
36.3.6 将邻接列表转换为嵌套集合模型
36.4 其他表现树和层次结构的模型
第37章 SQL中的图
37.1 邻接列表模型图
37.1.1 SQL和邻接列表模型
37.1.2 路径与CTE
37.1.3 环状图
37.1.4 邻接矩阵模型
37.2 分割嵌套集合模型表示的图节点
37.2.1 图中的所有节点
37.2.2 路径端点
37.2.3 可达节点
37.2.4 边
37.2.5 入度和出度
37.2.6 源节点、汇聚节点、孤立节点和内部节点
37.2.7 将无环图转化为嵌套集合
37.3 多边形中的点
37.4 图论参考书目
第38章 时间查询
38.1 时间数学
38.2 个性化日历
38.3 时间序列
38.3.1 时间序列中的间隙
38.3.2 连续时间段
38.3.3 相邻事件中缺失的时间
38.3.4 查找日期
38.3.5 时间的起始点和结束点
38.3.6 开始时间和结束时间
38.4 儒略日
38.5 其他时间函数
38.6 星期
38.7 在表中对时间建模
38.8 日历辅助表
38.9 2000年问题
38.9.1 零
38.9.2 闰年
38.9.3 千年问题
38.9.4 旧数据中的怪异日期
38.9.5 后果
第39章 优化SQL
39.1 访问方法
39.1.1 顺序访问
39.1.2 索引访问
39.1.3 散列索引
39.1.4 位向量索引
39.2 如何建立索引
39.2.1 使用简单查询条件
39.2.2 简单字符串表达式
39.2.3 简单时间表达式
39.3 提供额外信息
39.4 谨慎建立多列索引
39.5 考察IN谓词
39.6 避免UNION
39.7 联结胜于嵌套查询
39.8 使用更少的语句
39.9 避免排序
39.10 避免交叉联结
39.11 了解优化器
39.12 在模式更改后重编译静态SQL
39.13 临时表有时能带来方便
39.14 更新统计数据
39.15 不要迷信较新的特性
- PC官方版
- 安卓官方手机版
- IOS官方手机版
 DJI 大疆飞行模拟1.4官方版
DJI 大疆飞行模拟1.4官方版
 联想一键禁止驱动更新工具2.26.1 中文绿色版
联想一键禁止驱动更新工具2.26.1 中文绿色版
 关闭硬盘盒自动休眠软件附教程
关闭硬盘盒自动休眠软件附教程
 ELM327驱动1.0 官方版
ELM327驱动1.0 官方版
 沃仕达IP Camera CGI应用指南
沃仕达IP Camera CGI应用指南
 PowerPCB电路设计实用教程pdf电子版
PowerPCB电路设计实用教程pdf电子版
 PowerPCB高速电子电路设计与应用pdf高清电子版
PowerPCB高速电子电路设计与应用pdf高清电子版
 电路及电工技术基础pdf高清电子版
电路及电工技术基础pdf高清电子版
 硬盘坏道修复教程doc 免费版
硬盘坏道修复教程doc 免费版
 Revit MEP入门教程官方版doc 最新版
Revit MEP入门教程官方版doc 最新版
 新编电脑组装与硬件维修从入门到精通pdf 高清免费版
新编电脑组装与硬件维修从入门到精通pdf 高清免费版
 硬件系统工程师宝典pdf免费电子版
硬件系统工程师宝典pdf免费电子版
 xbox one手柄连接电脑教程doc完整免费版
xbox one手柄连接电脑教程doc完整免费版
 硬件工程师入门教程pdf高清免费下载
硬件工程师入门教程pdf高清免费下载
 Hyper-v虚拟机如何访问USB设备doc完整版
Hyper-v虚拟机如何访问USB设备doc完整版
 电脑主板跳线的接法详解doc最新免费版
电脑主板跳线的接法详解doc最新免费版
 线性稳压器基础知识pdf完整版
线性稳压器基础知识pdf完整版
 ModelSim简明使用教程pdf版
ModelSim简明使用教程pdf版
 数字电子技术基础教程(阎石第5版)pdf版
数字电子技术基础教程(阎石第5版)pdf版
 电路第五版邱关源pdf高清免费版
电路第五版邱关源pdf高清免费版
 计算机组成与设计硬件软件接口第五版pdf附答案完整版
计算机组成与设计硬件软件接口第五版pdf附答案完整版
 金融炼金术(原版)pdf格式【中文完整版】
金融炼金术(原版)pdf格式【中文完整版】
 深入PHP面向对象模式与实践(中文第三版)pdf高清扫描版【完整版】
深入PHP面向对象模式与实践(中文第三版)pdf高清扫描版【完整版】
 HADOOP实战(中文第二版)pdf清晰完整电子版
HADOOP实战(中文第二版)pdf清晰完整电子版
 大数据时代 生活工作与思维的大变革pdf中文完整版免费下载
大数据时代 生活工作与思维的大变革pdf中文完整版免费下载
 U盘装系统(优盘安装操作系统)图解教程 PDFpdf完整高清版【附源代码】免费下载
U盘装系统(优盘安装操作系统)图解教程 PDFpdf完整高清版【附源代码】免费下载
 机械设计手册第五版电子版pdf高清免费版
机械设计手册第五版电子版pdf高清免费版
 证券分析第六版pdf格式高清免费版【完整版】
证券分析第六版pdf格式高清免费版【完整版】
 疯狂java讲义(第3版)pdf (中文版)电子版
疯狂java讲义(第3版)pdf (中文版)电子版





 明朝那些事儿无删减txt全集下载
明朝那些事儿无删减txt全集下载 JGJ145-2013混凝土结构后锚固技术规程pdf完
JGJ145-2013混凝土结构后锚固技术规程pdf完 公路养护安全作业规程JTG H30―2015pdf高清
公路养护安全作业规程JTG H30―2015pdf高清 课程表空白表格【免费下载版】
课程表空白表格【免费下载版】 装配式混凝土结构技术规程JGJ1-2014pdf电子
装配式混凝土结构技术规程JGJ1-2014pdf电子 混凝土强度检验评定标准GB/T50107-2010电子
混凝土强度检验评定标准GB/T50107-2010电子 标准视力表高清大图(A4打印版视力表)bmp格式
标准视力表高清大图(A4打印版视力表)bmp格式 普通混凝土配合比设计规程JGJ/55-2011pdf电
普通混凝土配合比设计规程JGJ/55-2011pdf电 热交换器GB/T151-2014pdf电子完整高清版免费
热交换器GB/T151-2014pdf电子完整高清版免费 钢筋焊接及验收规程JGJ18-2012pdf扫描高清版
钢筋焊接及验收规程JGJ18-2012pdf扫描高清版